Generative AI has moved past the curiosity phase. Pilot funding, strategy decks, and board-level commitments are now the standard at most enterprises.
The question is no longer whether to build with these models. It is what to build, and how reliably it runs once the demo lands.
Retrieval-Augmented Generation has become the default pattern for Enterprise AI.
The goal is straightforward: bring your own data, anchor a capable model to authoritative sources, and require grounded responses.
The pattern is widely adopted. The value proposition is real.
The gap between that pattern working in a lab and working in production is wider than most teams expect.
RAG is a solved retrieval problem and an open trust problem.
A hybrid retrieval pipeline may pass every development check yet return zero meaningful results under realistic query load.
A general-purpose PII filter may protect privacy on common text yet silently strip the domain-specific identifiers that anchor every answer.
None of these surface as explicit errors or system crashes. They emerge as silent failures—a gradual degradation in reliability that is invisible to standard monitoring.
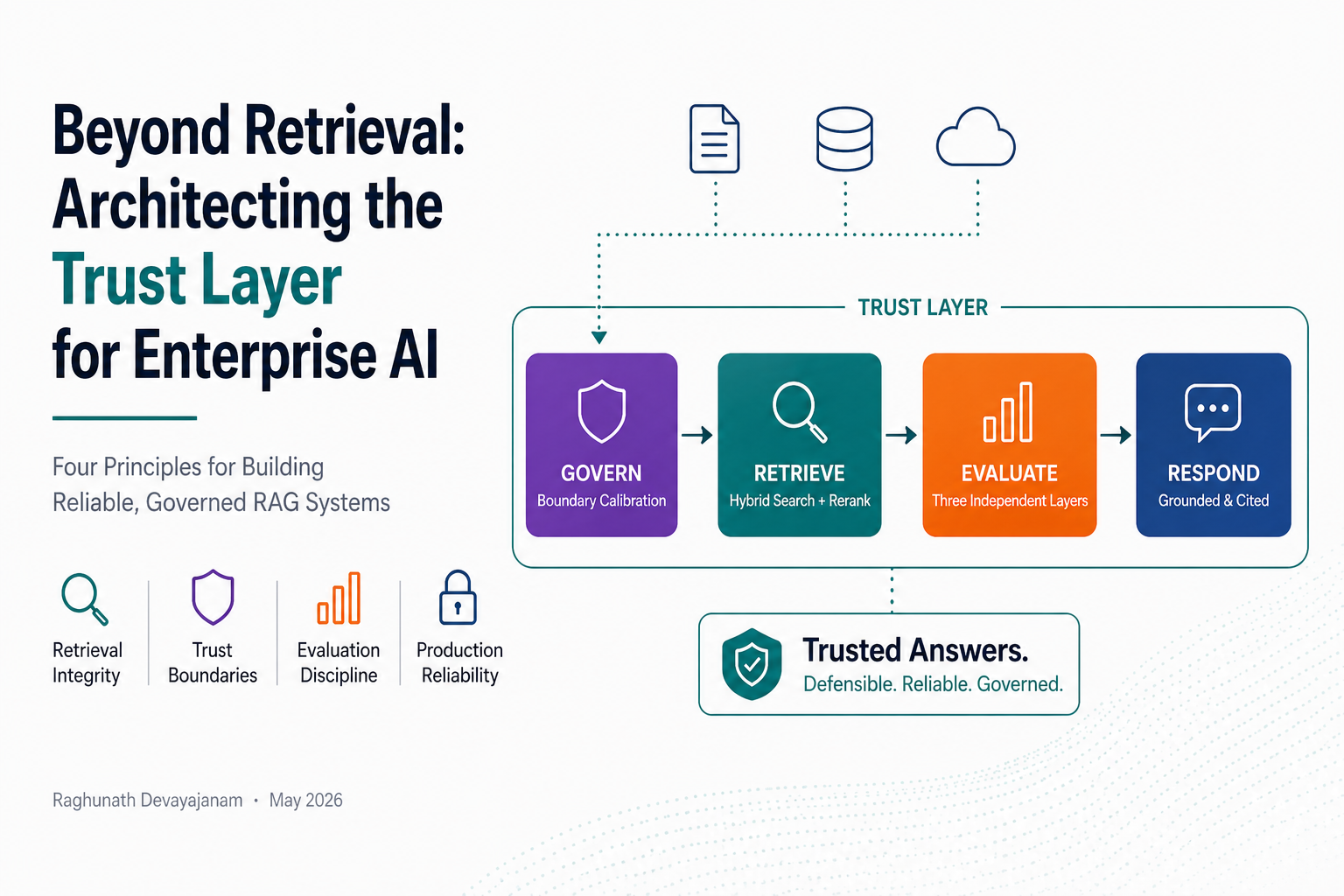
Four observations from the current state of production RAG architecture.
Below is the architecture that addresses these four failure modes as a single governed pipeline.
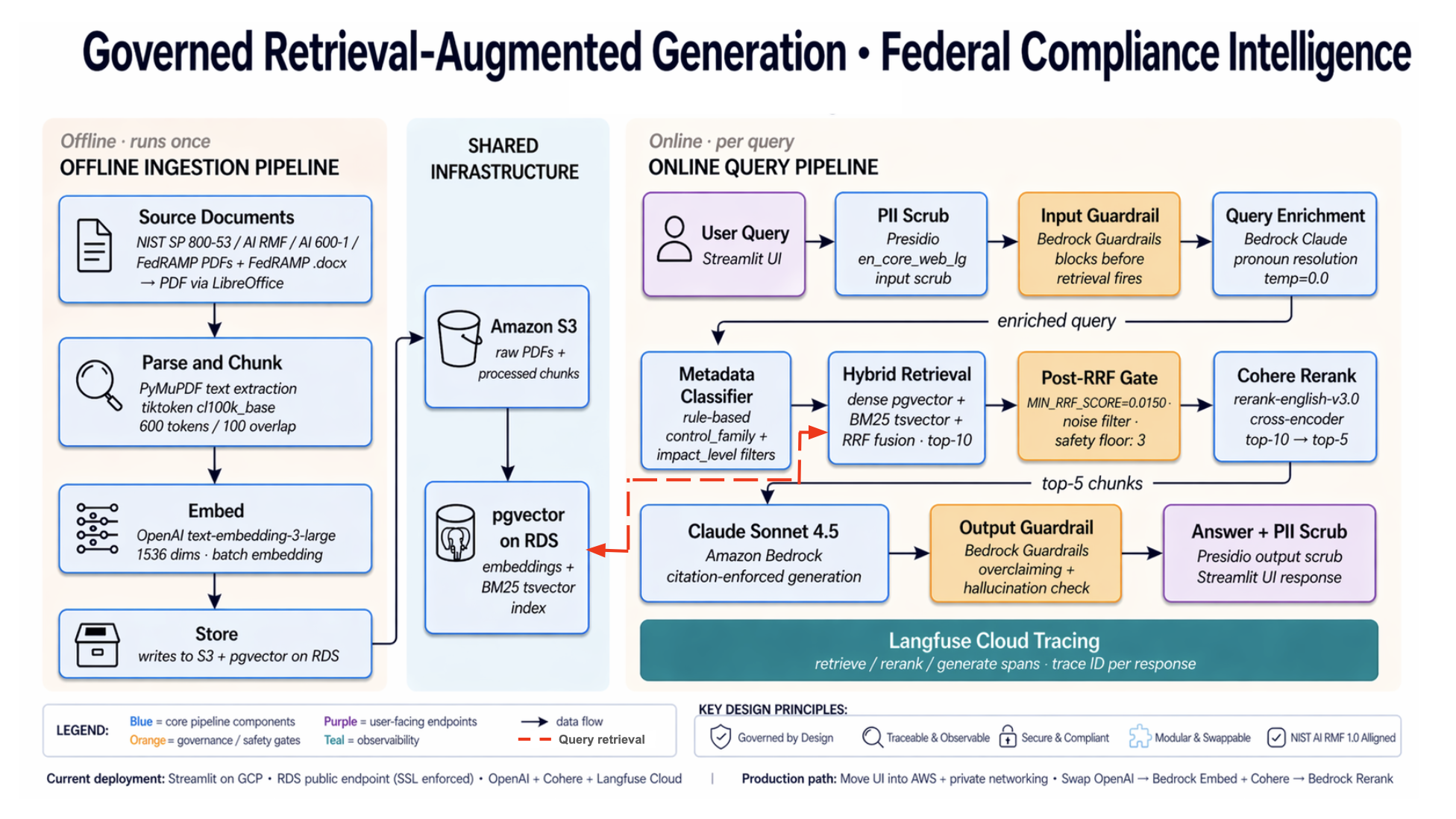
Each boundary in this pipeline is where a silent failure becomes visible — and where governance becomes enforceable.
1/4 — Retrieval Regressions Are Silent
Hybrid retrieval (Dense + BM25) is the production standard, but its failure mode is invisible. Keyword search engines often default to strict “AND” logic. Short developer queries match easily; long natural-language questions from real users often return zero results from the sparse leg.
The system doesn’t crash. It silently falls back to dense semantic search alone, losing the precision of exact technical terms.
If you aren’t validating sparse retrieval under realistic query loads, you aren’t running hybrid search.
2/4 — Installation Is Not Integration
Out-of-the-box PII filters are built for general English, not specialized domains. In federal compliance or medical research, technical identifiers — AC-2, NIST-800-53, ICD-10-CM — are semantically critical. A general classifier scrubs them before the retriever ever sees them.
A filter that blinds your search engine is a worse failure mode than one that lets PII through. One is a visible leak. The other is an undiagnosable system failure.
Installation is not integration. Every general-purpose component requires domain-specific calibration.
3/4 — Directness Is Not Quality
Standard RAG metrics reward directness. In governed domains, directness is often a liability. A compliance tool should hedge — responses like “this applies only under these conditions” are features, not bugs.
On a 20-question architect-level golden evaluation set: Faithfulness 0.90, Context Precision 0.94 — above target. Answer Relevancy 0.51–0.56 — below target, deliberately.
Evaluation strategy is part of the architecture, not a wrapper around it.
4/4 — Refusal Starts at Retrieval
Most teams treat output guardrails as the primary defense. A three-query out-of-scope suite ran through the full pipeline. All refused correctly. The output guardrail never fired. Top reranker scores were effectively zero. The model declined because there was nothing in context to overclaim from.
A team that invests in output filtering while accepting weak retrieval is solving the wrong problem.
The Blueprint
The Trust Layer isn’t a single feature. It’s the result of a multi-stage pipeline designed to protect data integrity at every boundary — retrieval integrity, domain calibration, evaluation discipline, and boundary enforcement working together.
These failure modes are not independent. They emerge from how the system is constructed.
An LLM reasoning over your enterprise corpus is one of the most valuable patterns in modern AI—whether that corpus is clinical trial results, legal precedent, compliance frameworks, customer history, or internal policy.
Reliability is what turns that capability into leverage.
Guardrails, evaluation discipline, observability, and boundary discipline are what produce reliability. Architecture is what makes them enforceable.
For enterprises where answer quality has consequences, the trust layer is the architecture. Everything else is just plumbing.
The question is not what Enterprise AI systems can produce. It is whether the result is grounded enough to defend.
Related
Reference implementation: The Trust Layer for Retrieval Systems